






Sunday, February 6. 2011
Paradox and Microsoft Access 2007 on Windows 7
First, my sympathies to anyone who still has to deal with Paradox databases. I recently setup Microsoft Access 2007 on a Windows 7 64-bit computer to manipulate data in an old Boreland Paradox database (from a limited user account). I consider this to be the computer equivalent of putting the engine from an old VW Beetle into a new Porche 914 (rather than the other way around)... but nonetheless, it has been done. The only serious problem was the following error message, which appeared upon opening the database from Access:
The cause was a series of permissions errors caused by the more strict access controls in Windows Vista/7. To fix the error perform the following steps:
- Grant write permissions for the user/group who will be running Access on
HKEY_LOCAL_MACHINE\SOFTWARE[\Wow6432Node]\Borland\Database Engine\Settingsin the Windows Registry. - Change the BDE configuration to avoid writing to C:\PDOXUSRS.NET
- Run "C:\Program Files (x86)\Common Files\Borland Shared\Bde\BDEADMIN.exe" as an Administrator
- Navigate to Configuration | Drivers | Native | Paradox
- Change the NET DIR parameter to somewhere writable (and shared between users). I created a folder in %systemdrive%\ProgramData.
- If necessary, grant write permissions on
HKEY_CLASSES_ROOT\.htmlin the Widnows Registry. I don't believe this was strictly required, but at one point I had enabled it during testing and am not completely certain if it was ruled out as a cause of the problem.
After performing the above steps, the error should be resolved. If not, I suggest using Process Monitor to look for permissions errors and attempt to resolve them (which is what I did). Best of luck.
Additional Information: Also, for those looking to the future, Access 2010 and later have dropped support Paradox 3-7, so further workarounds may be required.
Report Menu Disappeared from Visual Studio 2005
Recently, the "Report Menu" stopped appearing in the Main Menu in Visual Studio 2005 after focusing on the report designer surface (in an ASP.NET project). This is a rather significant problem for me, since I do not know of another way to modify report parameters and data sources....
I did a bit of digging through the activity log (as described in Troubleshooting Extensions with the Activity Log on the Visual Studio Blog, but found that the Microsoft Report Designer Package was loading without error. The real breakthrough came after watching devenv.exe in Process Monitor and watching it load the Visual Studio 2008 versions of Microsoft.ReportDesignerUI.dll and several others....
My guess is that the cause of the problem was installing Business Intelligence Development Studio with the "Advanced Services" skew of SQL Server 2008 R2 Express, which uses Visual Studio 2008 and a version of the Microsoft Report Designer Package designed for that version of VS. However, I have not confirmed this absolutely, because I need the newer version for another project. So, instead, I will bite the bullet and upgrade all of my Report Viewer 2005 reports to Report Viewer 2008. At least then I can edit them in Visual Studio 2010 (did I mention Report Designer 2008 - in VS 2010 - won't edit/save 2005 files?).
In case this sounds like a familiar gripe, I had similar problems with incompatible library versions in Microsoft Access.
Tuesday, November 23. 2010
Indexes on Linked Tables/Views in Access
Access has 2 distinct notions of an index on a linked table/view. The first is a "true" index, which resides in the linked database and is not used/modified directly by Jet/Access. These "true" indexes can be used by the database engine for executing query plans and are enforced during data modification (e.g. for uniqueness). The second is a "pseudo-index" which is "a dynamic cross-reference" that Jet/Access creates/maintains to facilitate data modification on linked tables/views which lack a unique index in the linked database. Constraints in pseudo-indexes can not be enforced outside of Access (and I am unsure if they are even enforced within Access) and are not used during query execution on the linked database (of course, although I have no knowledge of how they are used within Access...).
How to add indexes to linked tables/views
Create the indexes in the linked database (e.g. SQL Server) and refresh the table/view link (using Linked Table Manager or programmatically with TableDef.RefreshLink).
How to add pseudo-indexes to linked tables/views
When a link to a table/view without an index is created, Access prompts the user with a "Select Unique Record Identifier" dialog box (which is also triggered from code using DoCmd.TransferDatabase to create the link). Simply select the fields to be included in the index. Note that when creating the table using DAO/ADOX methods, this dialog is not presented and the pseudo-index is not created. Also, attempting to add an index to a linked table using DAO/ADOX results in an error (similarly to attempting to add an index through the table designer). To create the pseudo-index programmatically use Database.Execute to run a CREATE INDEX statement on the linked table/view. Jet will decide that the index must be a pseudo-index and create one.
Why pseudo-indexes?
There are several situations where an index in the linked database is not desirable. Particularly on updateable views where the underlying table(s) are updated frequently. Creating an indexed view has the side effect of materializing the table on disk, which requires every update to the underlying tables to involve multiple writes to disk as both the original table and the indexed view are updated. Yet, without a pseudo-index, the view would not be updateable from Access. So in these situations a pseudo-index is required.
Caveats
Unfortunately, pseudo-indexes are not preserved when the linked table connection is updated. So for any scripts which modify the connection (e.g. to re-point a table to a different server) must recreate the indexes after refreshing the link. The following code is a general outline for what is required (note that index direction is not currently preserved). The code should be run on the index before the connection is updated, then the returned SQL run after the connection is changed and the link is refreshed:
function indexToSQL(index, tableName) {
var e, query;
query = new Array();
query.push("CREATE ");
if (index.Unique) {
query.push("UNIQUE ");
}
query.push("INDEX ");
query.push(index.Name);
query.push(" ON ");
query.push(tableName);
query.push(" (");
for (e = new Enumerator(index.Fields); !e.atEnd(); e.moveNext()) {
query.push(e.item().Name);
query.push(", ");
}
query.pop();
query.push(") ");
if (index.IgnoreNulls || index.Primary || index.Required) {
query.push("WITH ");
if (index.IgnoreNulls) {
query.push("IGNORE NULL ");
}
if (index.Primary) {
query.push("PRIMARY ");
}
if (index.Required) {
query.push("DISALLOW NULL ");
}
}
return query.join("");
}
Friday, November 12. 2010
Access Data Pages in Access 2002/2003 on Windows Vista/7
For anyone who has tried creating a blank Access Data Page in Access 2003 (or Access 2002 aka Access XP) on Windows Vista or 7, you will have seen the following message:
Wednesday, November 10. 2010
Access 2003 Not Compatible with Access Runtime 2010
Just a quick warning: Don't install Access Runtime 2010 on any computer where you are still using Access 2003 (this may apply to other version combinations as well). I recently installed the latest version of SQL Server Migration Assistant for Access, which requires the Microsoft Access 2010 Runtime. After installing the runtime, creating an event procedure would cause Access 2003 to crash. With a bit more testing, I found that the Visual Basic Editor was automatically creating a reference to the "Microsoft Access 14.0 Object Library" (that came with the 2010 Runtime) instead of the "Microsoft Access 11.0 Object Library" (that came with Access 2003) and it would not allow me to change this library. After removing the 2010 runtime, all is back to normal.
Wednesday, October 20. 2010
The Curious Case of OBJC_DISABLE_GC in OCUnit tests
When I first started writing unit tests using the OCUnit testing framework, my unit tests were failing when I ran them, but when I set break points to debug them they started passing. It turned out, after much swearing and frustration, that there were errors being spewed to the standard error file handle. This error looked a little something like this:
GC: forcing GC OFF because OBJC_DISABLE_GC is set
Normally this wouldn't be a big deal, and my application at it core relies on reading messages from both standard out and standard error as part of communicating with an NSTask object. I'm using RegexKit in order to parse the output into a meaningful set of data, and that's where the problem manifests itself. Since this error is coming from the unit testing harness and my regex's are not expecting this error message in the standard error file handle, this led to failed unit tests.
Naturally, I immediately started googling for the answer, and read posts every from CocoaBuilder to StackOverflow, and everyone suggested to change the Garbage Collection behavior from Unsupported to either Supported or Required. Easy enough, and so I did, in these steps:
- Double click on the project at the top of the project browser
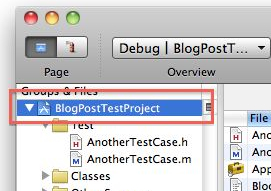
- Find the garbage collection setting
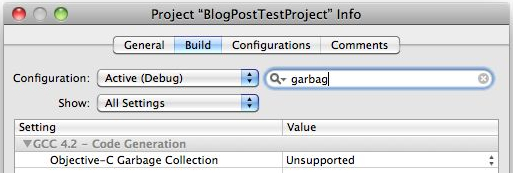
- Change the value to either supported or required (supported in my case, as I'm actually using the retain count method)
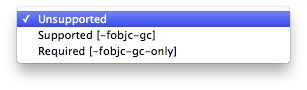
Done and done...or so I thought. I ran my unit test again, and I continued to get the same error message. I switched the garbage collection setting to the other value (required in my case) and still I continued to get the error message.
So, I went back on the hunt for the answer and the same answer came up again and again, "Switch your garbage collection setting", which was not solving my problem. In the end, I did end up solving my problem and the answer is indeed "switch your garbage collection setting" but one thing no one told me, and I'm here to tell everyone having the same problem as I was having, is exactly WHICH garbage collection setting to change.
The secret it turns out is that the Unit Test Bundle has its own garbage collection setting, and its not inherited from the project level setting.
So, instead of double click on the project, double click HERE:
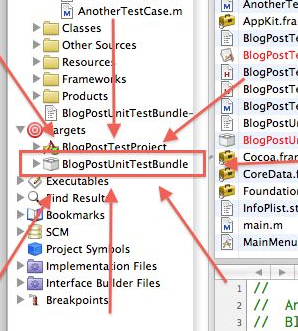
and change that garbage collection setting to either Supported or Required, per normal:
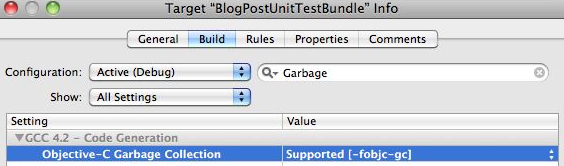
The instant I changed the unit test bundle's setting, the errors in standard out that I'm not expecting are gone.
Friday, October 15. 2010
The proper care and feeding of NSWindow objects display as a sheet
The Too Long, Didn't Read version:
Displaying a NSWindow, one that's lazily loaded from its own nib file, as a sheet doesn't have a any method for notifying observers that its about to be displayed, and therefore its difficult to reset the sheet UI on the second and later displays. Therefore, use this NSWindow subclass as your controller to re-set the UI right before the window will display as a sheet.
---
The long version wherein I lead the reader, step by step, through the problem and the solution to lazily-loaded, re-usable NSWindow objects displayed as a sheet:
In many examples of using custom NSWindow object displays as a sheet in a Cocoa application, found both on the web and in print, the author has placed the NSWindow object that will be used as a sheet inside in the .nib file of the window that the sheet will be attached to. This works fine if the sheet is guaranteed to be displayed to the user. On the other hand if you can't guarantee that the user will see the sheet, as you frequently cannot with a sheet, including the sheet in the nib file violates the guideline of "For a window or menu that is used only occasionally, store it in a separate nib file. By storing it in a separate nib file, you load the resource into memory only if it is actually used."
As a tangential discussion before diving into the main point, everytime you load a resource from a nib file all objects contained within the file, with the exception of the 'File's Owner', 'First Responder' and 'Application' objects since these are proxy objects, are unarchived and have their connections (both IBAction and IBOutlets) set up. Therefore, even if you don't use a particular resource contained with in the nib, such as in the case where the sheet is never presented to the user, the program has wasted both computation time and memory loading all the unused objects anyway. The more you can get away with not loading from your nib files, the faster your program will launch and the more memory efficient it will be while running. As such, the best way to handle NSWindow objects that may not be displayed to the user is to move them into their own nib file and only load them from the nib file when, and if, they need to be displayed to the user. For a more complete run down of the ins and outs of nib files please read through Apple's Resource Programming Guide.
So, in the case of a custom sheet, since we don't want to waste processing time and system memory until we need it, the best way to handle this is as follows. I'm purposefully omitting the corresponding .h files for this example since they're rather trivial. The only important part is that both MainWindowController and SheetController are both subclasses of NSWindowController:
MainWindowController.mSheetController* sheetController = [[SheetController alloc] init];
[NSApp beginSheet:[sheetController window]
modalForWindow:[self window]
modalDelegate:self
didEndSelector:@selector(sheetDidEnd:returnCode:contextInfo:)
contextInfo:sheetController];
}
- (void)sheetDidEnd:(NSAlert*)alert returnCode:(NSInteger)returnCode
contextInfo:(void*)contextInfo {
// do something with the user input to the sheet here
SheetController* sheetController = contextInfo;
[sheetController release];
}
self = [super initWithWindowNibName:@"someSheet"];
return self;
}
- (IBAction)dimissSheet:(id)sender {
[NSApp endSheet:[self window] returnCode:NSOKButton];
[[self window] orderOut:self];
}
This is just sample code, with just enough to show how displaying a sheet would work. Obviously it will work, but there's a subtle error in here that's easy to miss for new programmers. Everytime [[SheetController alloc] init] is called in the main window controller, the contents of the nib containing the sheet is opened, unpacked, and hydrated. Even though we're properly lazily loading the objects in the nib file, we've committed another error. We're now incurring the nib loading everytime the sheet displays. It would be better if we could unpack this information from the nib only once, and reuse the sheet NSWindow object every time and therefore we only incur the cost of instantiation the first time a user needs the sheet.
Easy enough, in theory (you'll see why this turns out to be harder than it looks in a second), and with that change it looks something like this:
MainWindowController.h MainWindowController.mif (sheetController == nil) {
sheetController = [[SheetController alloc] init];
}
[NSApp beginSheet:[sheetController window]
modalForWindow:[self window]
modalDelegate:self
didEndSelector:@selector(sheetDidEnd:returnCode:contextInfo:)
contextInfo:sheetController];
}
- (void)sheetDidEnd:(NSAlert*)alert returnCode:(NSInteger)returnCode
contextInfo:(void*)contextInfo {
// do something with the user input to the sheet here
}
self = [super initWithWindowNibName:@"someSheet"];
return self;
}
- (IBAction)dimissSheet:(id)sender {
[NSApp endSheet:[self window] returnCode:NSOKButton];
[[self window] orderOut:self];
}
Now, we're creating the sheet a single time, which fixes the problem of loading the resources from the nib every time you display the sheet, but introduces a new problem (one that's hard to see from the example code without running a full application that implements this code). The problem is that because we're using the exact same NSWindow object over and over, if the sheet contains UI elements that the user can change (NSTextField, NSSlider, NSPopupButton, etc.) then those UI elements will be displayed as the user left them from the first time they interacted with the sheet. Sometimes this is the desired behavior, but in the event that its not, you have a problem.
Normally in the case where you want to re-use a window over and over and want to reset its UI every time its presented to the user, you can override the - (IBAction)showWindow:(id)sender method in the NSWindowController. Unfortunately for a NSWindow displayed as a sheet, the showWindow: method is not invoked by [NSApp beginSheet:...] and therefore your NSWindowController subclass isn't notified that the window is about to be displayed. This lack of notification just prior to the window showing on screen as a sheet is the heart of the problem. As a quick rundown of the methods you might think work but don't:
- When the sheet is loaded, it invokes
windowDidLoad:on its controller, but this only happens the first time its loaded from the nib and is never invoked again (since we're re-using the sheet and only loading it from the nib a single time), so it can't be used to reset the UI for the second display of the sheet. - The NSWindow that will have a sheet attached to it notifies its delegate that its about to display a sheet through the
willDisplaySheet:(NSNotification*)method, but the notification contains a nil userInfo dictionary so it doesn't contain a pointer to the sheet its about to display - You might think that when a window's delegate receives a
willDisplaySheet:notification the delegate could invoke theattachedSheetmethod on the window that's about to display a sheet. Unfortunately, the NSWindow'sattachedSheetmethod returnsnilat this point since the sheet isn't yet attached. - You could override
[controller window]method on the NSWindowController for the sheet in order to reset the UI before returning the window object. This partially works since you'll reset the UI as part of the[NSApp beginSheet:[sheetController window] ...]invocation, but it also means you lose access to what the user did on the other side since dismissing the sheet through[NSApp endSheet:[self window] ...]also resets the UI.
Since the last bullet point is half usable, it turns out that with the right tweaks, we can avoid restting the UI while dismissing the sheet. I now present the DESSheetController, which you can use in your own Xcode project to fix this issue:
DESSheetController.h// DESSheetController.m
//
// Created by Peter Nix (pnix@digitalenginesoftware.com)
//
#import <Cocoa/Cocoa.h>
/*!
@class DESSheetController
@abstract An abstract super class to use instead of NSWindowController to
assist in using sheets.
@discussion Using an NSWindow controller loaded from its own nib as a sheet
(a distinct nib from the window its going to attach to) doesn't have a good
notification to its NSWindowController or delegate that its about to display.
Therefore, it is very difficult to reset the UI to a default state when re-displaying
the sheet to the user. This class provides the necessary overrides and callbacks
to help reset the UI to a default state when reusing the same NSWindow
object as a sheet.
@updated 2010-10-13
*/
@interface DESSheetController : NSWindowController {
}
/*!
@abstract dismissSheet: provides a way of dismissing the sheet without losing
the information contained in the UI elements the user can interact with.
@discussion Based on the override of the window method (see the implementation
file) if you call [self window] as part of the call to dismiss the sheet, you will
reset the UI on the sheet before you query for this information in your modal
delegate's selector callback. Therefore, the contract for overriding this class
for a custom sheet controller is call this method when dismissing the sheet
in order to preserve the UI state.
@param returnCode the integer indicating the status that the sheet ended with.
This parameter will be passed onto NSApp when sending the sheet out and in
turn gets passed to the modal delegate's callback selector.
*/
- (void)dismissSheet:(NSInteger)returnCode;
/*!
@abstract This is the method that needs to be overriden in your custom subclass
in order to reset the UI when redisplaying the sheet.
@discussion This method is invoked in the middle of returning the window from
your controller to the NSApp instance to begin a sheet. Therefore this method
is invoked at (literally) the last possible moment, meaning that all the UI for
the sheet has been properly hydrated from the nib, and is just about to be
displayed as a sheet. This method is empty in this class, and is designed to be
overridden by a custom subclass in order to perform any UI clean up in order
to get the sheet into a reset/clean state for display to the user.
*/
- (void)hydrateView;
@end
@implementation DESSheetController
#pragma mark inherited methods
- (NSWindow*)window {
NSWindow* window = [super window];
[self hydrateView];
return window;
}
#pragma mark private methods
- (void)hydrateView {
// do nothing by design, overridden by sub-classes
}
- (void)dismissSheet:(NSInteger)returnCode {
// note the use of super instead of self in order to bypass the sheet reset code
// via the hydrateView method
[NSApp endSheet:[super window] returnCode:returnCode];
[[super window] orderOut:self];
}
@end
So, now for a bit of explanation. The point is to use this class as your sheet controller's superclass instead of NSWindowController. By subclassing DESSheetController, all you have to do is implement -(void)hydrateView within your subclass and use that method to re-initialize the UI everytime the sheet is displayed. On the outgoing side, the contract is to invoke the - (void)dismissSheet:(NSInteger)returnCode method instead of invoking [NSApp endSheet:] directly in your subclass. The dismissSheet: method calls [super window] instead of [self window] and therefore avoids resetting the UI before the modal delegate can query the sheet for information.
Now, you can safely re-use a single NSWindow as a custom sheet for user interaction over and over again, and still stick to lazy initialization and avoid multiple nib loading.
Friday, August 13. 2010
Passing pipes to subprocesses in Python in Windows
Passing pipes around in Windows is a bit more complicated than it is in Unix-like operating systems. This post is a bit of information about how file descriptor inheritance works in Windows and a quick example of how to do it.
The first difficulty to overcome is that file descriptors are not inherited by subprocesses in Windows as they are in Linux. However, OS file handles can be inheritable, and it is possible to retrieve the OS file handle associated with a C file descriptor using the _get_osfhandle function. It is also possible to convert the OS file handle back to a C file descriptor in the child process using _open_osfhandle. However, the OS file handle is not inheritable (see Python Bug 4708 - although on a side note, I don't think they should be default-inheritable since there is no preexec_fn in which to close them and prevent deadlock situations where a child holds the write end of a pipe open, but that is another matter), so to get an inheritable OS file handle it must be duplicated using DuplicateHandle.
The operating system-specific functions described above can be accessed through the _subprocess and msvcrt modules. Their use can be seen in the source for the subprocess module, if desired. However, note that the interface in _subprocess is not stable and should not be depended on, but since there is no alternative (that I am aware of - short of writing another module in C) it is the best solution. Now, an example:
parent.py:
import os
import subprocess
import sys
if sys.platform == "win32":
import msvcrt
import _subprocess
else:
import fcntl
# Create pipe for communication
pipeout, pipein = os.pipe()
# Prepare to pass to child process
if sys.platform == "win32":
curproc = _subprocess.GetCurrentProcess()
pipeouth = msvcrt.get_osfhandle(pipeout)
pipeoutih = _subprocess.DuplicateHandle(curproc, pipeouth, curproc, 0, 1,
_subprocess.DUPLICATE_SAME_ACCESS)
pipearg = str(int(pipeoutih))
else:
pipearg = str(pipeout)
# Must close pipe input if child will block waiting for end
# Can also be closed in a preexec_fn passed to subprocess.Popen
fcntl.fcntl(pipein, fcntl.F_SETFD, fcntl.FD_CLOEXEC)
# Start child with argument indicating which FD/FH to read from
subproc = subprocess.Popen(['python', 'child.py', pipearg], close_fds=False)
# Close read end of pipe in parent
os.close(pipeout)
if sys.platform == "win32":
pipeoutih.Close()
# Write to child (could be done with os.write, without os.fdopen)
pipefh = os.fdopen(pipein, 'w')
pipefh.write("Hello from parent.")
pipefh.close()
# Wait for the child to finish
subproc.wait()
child.py:
import os
import sys
if sys.platform == "win32":
import msvcrt
# Get file descriptor from argument
pipearg = int(sys.argv[1])
if sys.platform == "win32":
pipeoutfd = msvcrt.open_osfhandle(pipearg)
else:
pipeoutfd = pipearg
# Read from pipe
# Note: Could be done with os.read/os.close directly, instead of os.fdopen
pipeout = os.fdopen(pipeoutfd, 'r')
print pipeout.read()
pipeout.close()
Note: For this example to work, python must be on on the executable search path (i.e. in the %PATH% environment variable). If it is not, change the subprocess invocation to include the full path to python.exe. Note also that there is some complication with OS file handle leakage. When a _subprocess_handle object is garbage collected the handle that it holds is closed, unless it has been attached. Therefore, if the subprocess will outlive the scope in which the handle variable is defined, it must be detached (by calling its Detach method) to prevent closing during garbage collection. But this solution has its own problems as there is no way (that I am aware of) to close the handle from the child process, which means a file handle will be leaked.
Above caveats aside, this method does work for passing pipes between parent and child processes on Windows. I hope you find it useful.
Sunday, July 11. 2010
Clone Only HEAD Using Git-SVN
A quick tip for git-svn users: When checking out an SVN repository where only the HEAD revision is desired, the following snippet may be useful:
git svn clone -$(svn log -q --limit 1 $SVN_URL | awk '/^r/{print $1}') $SVN_URL
The above snippet determines the most recent SVN revision number (using svn log) and passes it to git-svn-clone. This can also be added to git as an alias by adding the following to .gitconfig:
[alias]
svn-clone-head = "!f() { git svn clone -`svn log -q --limit 1 $1 | awk '/^r/{print $1}'` $1 $2; }; f"
For checking out the last $N commits, a similar convention can be used:
git svn clone -$(svn log -q --limit $N $SVN_URL | awk '/^r/{rev=$1};END{print rev}') $SVN_URL
Friday, July 9. 2010
HttpHandlers in Virtual Directories on IIS6
Background
I recently encountered an interesting problem related to how Virtual Directories interact with web.config when dealing with an HttpHandler. The website was virtually rooted at "/webapp", physically rooted at "C:\inetpub\wwwroot\webapp". Inside the application, I wanted "files" ("/webapp/files") to be physically rooted on another drive at "E:\files" so that large data files could be stored on a more appropriate drive. Furthermore, I wanted a custom Http Handler which would generate a few files inside "files" on the fly. Initially, this was setup by creating a virtual directory named "files" which pointed to "E:\files", the HttpHandler was placed in App_Code, and web.config contained the following:
<?xml version="1.0"?>
<configuration xmlns="http://schemas.microsoft.com/.NetConfiguration/v2.0">
<system.web>
<httpHandlers>
<add verb="GET" path="files/generated.txt" type="WebApp.MyHttpHandler" />
</httpHandlers>
</system.web>
</configuration>
The Problem
As I quickly found out, this doesn't work (for several reasons, as we will see). First, requests for .txt files are not handled by isapi_aspnet.dll (by default), so whatever is done in the ASP.NET code is irrelevant because IIS will not call ASP.NET to handle the request. To fix this problem, the .txt extension can be added to the list of extensions handled by isapi_aspnet.dll (which will cause extra overhead as each request is run through the ASP.NET ISAPI handler, even when the file exists on disk) or the extension of the generated file can be changed to something mapped to isapi_aspnet.dll (like .aspx).
Next, unless the content of "files" is going to be substantially different from the rest of the application, the "files" Virtual Directory must not be a Virtual Application. If the "files" mapping is really a Virtual Application, it will not share code with the parent application so the HttpHandler class will not be found.
Finally, due to how the ASP.NET Configuration File Hierarchy and Inheritance works, web.config will be (essentially) re-applied in the virtual directory, so "files/generated.aspx" will be "files/files/generated.aspx" when considered from inside of the "files" virtual directory. To fix this (while not also creating a "/generated.aspx" alias as well), remove the httpHandlers section in the global web.config and create a web.config inside of the physical directory for "files" with path="generated.aspx"
Once all of the above steps are completed, the generated file should appear correctly and everything should be golden. If not, I strongly recommend replacing the real content of the custom HttpHandler with code that simply writes a string to the response and exits. This way any internal errors in the HttpHandler will not confound any issues with whether or not the handler is being called.
Thursday, July 8. 2010
Microsoft Sync Framework (v2) Not Thread Friendly
As a quick note for other developers that may be getting the same (difficult to understand) error, the Microsoft Sync Framework version 2 is not as thread-friendly as one might expect. The API documentation makes it clear that class instances in the framework are not thread-safe, however, this thread-unsafety goes farther. Even when the instance is protected by proper locking to prevent concurrent access, it may still error when accessed from multiple threads. For example, if a SyncOrchestrator and 2 FileSyncProviders are initialized on one thread and (later) Synchronize is called from another thread, the following exception will be thrown:
System.InvalidCastException: Specified cast is not valid.
at Microsoft.Synchronization.CoreInterop.SyncServicesClass.CreateSyncSession(ISyncProvider pDestinationProvider, ISyncProvider pSourceProvider)
at Microsoft.Synchronization.KnowledgeSyncOrchestrator.DoOneWaySyncHelper(SyncIdFormatGroup sourceIdFormats, SyncIdFormatGroup destinationIdFormats, KnowledgeSyncProviderConfiguration destinationConfiguration, SyncCallbacks DestinationCallbacks, ISyncProvider sourceProxy, ISyncProvider destinationProxy, ChangeDataAdapter callbackChangeDataAdapter, SyncDataConverter conflictDataConverter, Int32& changesApplied, Int32& changesFailed)
at Microsoft.Synchronization.KnowledgeSyncOrchestrator.DoOneWayKnowledgeSync(SyncDataConverter sourceConverter, SyncDataConverter destinationConverter, SyncProvider sourceProvider, SyncProvider destinationProvider, Int32& changesApplied, Int32& changesFailed)
at Microsoft.Synchronization.KnowledgeSyncOrchestrator.Synchronize()
at Microsoft.Synchronization.SyncOrchestrator.Synchronize()
at DigitalEngine.SyncMgrFileSync.SyncItem.Synchronize() in File.cs:line num
To work around such errors, make sure all sync instances are only accessed from a single thread.
Thursday, June 10. 2010
Non-strongly typed attributes in ASP.NET
Wednesday, May 12. 2010
Proper Error Page Handling in ASP.NET
ASP.NET provides a convenient mechanism for configuring error pages through the customErrors element of web.config, which allows developers to select pages to be displayed based on the error code the server would have generated. However, this mechanism has some serious drawbacks. Most importantly, the error code is no longer sent to the browser! For example, when a custom error page is used and a 500 error occurs, instead of sending HTTP status code 500 to the browser, ASP.NET will send a 302 redirect to the browser (and a 200 on the error page, assuming it does not throw an error itself). In my opinion, this is completely wrong and misleading. Although the users see an error page, the software (unless it has custom logic to detect the error page by URL or by title/keyword search) is told that everything is working as expected and that the page has temporarily moved. It's poor practice for search optimization (although I'm sure major search providers have long ago written logic to recognize this sort of misinformation) and it's poor practice for any automated consumers of the site.
To fix this, I highly recommend writing some custom error handling logic. There is lots of useful information to get started in the Rich Custom Error Handling with ASP.NET article on MSDN (as long as the suggestions to use Response.Redirect are ignored). I recommend that the fundamental component of the error handling should be something like the following (in Global.asax):
void Application_Error(object sender, EventArgs e)
{
// Insert any logging or special handling for specific errors here...
Response.StatusCode = (int)System.Net.HttpStatusCode.InternalServerError;
Server.Transfer("~/Errors/ServerError.aspx");
}
Using the above code, the server will respond with HTTP status code 500 and a useful error page to tell users what happened and what they can do about it. It will also not mess with their browser URL so that they can easily retry the page and/or explain what happened and where to a tech.
Notes:
Note1: Make sure the error page is larger than 512 bytes, otherwise IE and Chrome will not show it in their default settings.
Note2: The HTTP 1.1 status codes and their meanings are described in Section 10 of RFC2616.
Tuesday, May 11. 2010
Making Custom Replication Resolvers Work in SQL Server 2005
Background
SQL Server provides a very convenient method for implementing custom business logic in coordination with the synchronization/merge process of replication. For tasks which need to be done as data is synchronized, or decisions about resolving conflicts which are business-specific, implementing a custom resolver is a surprisingly straight-forward way to go. For more information, check out the following resources:
- How to: Implement a Business Logic Handler for a Merge Article (Replication Programming)
- How to: Implement a COM-Based Custom Conflict Resolver for a Merge Article (Replication Programming)
- BusinessLogicModule Class
Making It Work
Things are never quite as easy as they seem... Chances are, some sort of error message was generated once the DLL was deployed and the instructions in (1) were completed. For example, the following error is common:
Don't Panic. First, check that the DLL has been placed in the directory containing the merge agent on the subscriber (assuming this is being done with pull - place the DLL on the server for push) or registered in the GAC. This message can also indicate dependency problems for the DLL where dependent libraries can't be found/loaded. One way to test that the assembly can be loaded is to compile and run the following program in the same directory as the merge agent:
class Program
{
static void Main(string[] args)
{
TryLoadType(ASSEMBLY_NAME, CLASS_NAME);
// Leave window visible for non-CLI users
Console.ReadKey();
}
static void TryLoadType(string assemblyname, string typename)
{
try
{
Assembly asm = Assembly.Load(assemblyname);
if (asm == null)
{
Console.WriteLine("Failed to load assembly");
return;
}
Type type = asm.GetType(typename);
if (type == null)
{
Console.WriteLine("Failed to load type");
return;
}
ConstructorInfo constr = type.GetConstructor(new Type[0]);
if (constr == null)
{
Console.WriteLine("Failed to find 0-argument constructor");
return;
}
object instance = constr.Invoke(new object[0]);
Console.WriteLine("Successfully loaded " + type.Name);
}
catch (Exception ex)
{
Console.Error.WriteLine("Error loading type: " + ex.Message);
}
}
}
Note: It is very important to correctly determine where the merge agent executable is and where it is being run from when testing. The DLL search path includes both the directory in which the executable file exists and the directory from which it is run (for weak-named assemblies). replmerg.exe usually lives in C:\Program Files\Microsoft SQL Server\90\COM, but mobsync.exe (if you are using Synchronization Manager or Sync Center) is in C:\WINDOWS\system32, and this will have an effect on the assembly search path.
Make sure the names are exactly as they were specified in sp_registercustomresolver. If the problem was a misnamed assembly or class (because you are like me and fat-fingered the name...) here's how you fix it: sp_registercustomresolver can be re-run with the same @article_resolver parameter to overwrite the information for that resolver. This overwrites the information stored in the registry at HKLM\SOFTWARE\Microsoft\Microsoft SQL Server\90\Replication\ArticleResolver (or a similar location for different versions/configurations). However, if the resolver has already been attached to an article, the information is also stored in sysmergearticles in the article_resolver (assembly name), resolver_clsid (CLSID), and resolver_info (.NET class name) columns. So, run an UPDATE on these columns to fix errors, as appropriate.
Good Luck!
Thursday, March 25. 2010
Java PermGen space, memory leaks, and debug mode
Over the last couple of days of development on a Java web application using the Wicket framework, I noticed a peculiar behavior on the server while in debug mode. After several redeployments of the application war file to the Tomcat server (without restarting the server), eventually a page reload would hang and the server would start spewing java.lang.OutOfMemoryError: PermGen space stack traces to the console. Clearly this is indicating a memory leak somewhere in my code or in the libraries my code relies on and on top of that, this isn't the sort of memory leak usually associated with poor memory management, since this is the PermGen space not the Heap space which is running out. Since PermGen is a special place in memory for ClassLoader objects to reside, its not something that most memory profilers will pick up since it shouldn't ever be a problem for normal code.
At this point, after searching for information on what would cause PermGen space to run out, and reading a bunch of mixed responses (most programmers that have blogged about this before me seem to take the head in the sand approach and just increase the PermGen size so that won't run out as fast), I found these two wonderful blog posts by Frank Kieviet. He's analysis of the situation is very enlightened and helped me understand what was going on behind the scenes.
So, using Sun's VisualVM tool, I started profiling the PermGen space of my local Tomcat install while continually deploying and redeploying the code base. Sure enough, every time I changed the code and eclipse automatically redeployed the code to the Tomcat instance, the PermGen size would increase the next time I requested a page and Tomcat started allocating objects. No matter how long I waited or clicked the garbage collect button, the PermGen space was never reclaimed and eventually I'd hit the memory ceiling and the server would start spewing those familiar OutOfMemoryError messages again.
Having read Frank's excellent analysis of static references, I took a trip through the code base in order to find offending static object references that might be causing the leak. Unfortunately, no where in the code was I creating static references that looked like they would have resulted in a ClassLoader leak (not to say that there aren't, as was pointed out in Frank's article, this is a tricky problem to track down and none of my references looked suspicious). Well, if its not in my code, where is it?
Since I'm using Wicket, I created a skeletal test project that creates a single webpage and dynamically sets a span tag on the page to a hard coded String object. I fired up VisualVM, and ran my same deploy and redeploy test and sure enough the PermGen space starts getting eaten up like clockwork. To be fair, the PermGen space didn't fill up nearly as fast since my test project is only allocating a few classes and they're associated ClassLoader objects every redeploy, but given enough time it did eventually result in the same OutOfMemoryErrors in the console.
"Aha!", I thought, "Wicket's developers have made a grievous mistake, and aren't watching their code for potential ClassLoader leaks". I figured that since I'm using Wicket, I'll just have to live with the knowledge that eventually I'll run out of PermGen space and have to restart my server. Certainly annoying to me as a developer, but its definitely a viable workaround. The only problem will be when this code hits production, and I'll have to be careful to restart the server after each code deployment or run the risk of having the server be brought to its knees from memory problems.
I can't remember what particular Google search netted me this link, but I did eventually find this gem of information:
The JDK's permanent memory behaves differently depending on whether a debugging is enable, i.e. if there is an active agent.
If there is an active agent, the JDK can fail to collect permanent memory in some cases. (Specifically, when some code introspects a class with a primitive array like, byte[] or char[].) This can cause the permanent space to run out, for example, when redeploying .war files.
I had no idea that the JVM's garbage collector behaved differently depending on whether the application is running in debug mode or not. Since I'm constantly running my code in debug mode and using Eclipse's hot fix code replace feature, and every code change redeploys the entire .war archive to the server, resulting in more class loaders on the class path, and another chunk of memory that will never be reclaimed by the server.
Therefore, the moral of the story is while trying to track down memory leaks, do not run your application (especially a web application) in debug mode. It is still true that you can leak PermGen space without your application being run in debug mode, so this isn't an excuse for poor coding practices. Rather, its a cautionary tale of my part of how even a simple thing like running your application in debug mode can mean rather drastically different program performance even outside of the debug instruction overhead.

